Cómo es el primer día, comenzaremos desde el principio, una vez seleccionada la plantilla, con la que vamos a trabajar, he decidido empezar a elaborar la página de inicio, hemos cambiado el título, para comenzar con nuestra marca, en este caso de lentes para gafas.
DÍA 25/02
Hemos cambiado la barra de herramientas, le hemos añadido el nombre de la marca, le hemos cambiado las páginas del panel, cambiando la posición, los colores y el texto.
hemos cambiado el modelo y la letra del botón de comprar, y del carrito.
Hemos hecho el prototipo del producto a vender.
DÍA 1/3
Usando diversas aplicaciones hemos elaborado una foto de distintas gafas para mostrar los productos de la tienda.
personalizamos tanto el título principal como la descripción.
Vamos a explicar los beneficios y el funcionamiento de las lentes.
hemos optado por un estilo mas minimalista en la página, en la que predomina el blanco y el negro, junto con tonos azul-verdosos.
DÍA 6/3
Estamos terminando la página principal de inicio.
Hemos puesto las características básicas de las lentes.
Crearemos una subpágina dentro del inicio, para explicar los tipos de variaciones de las lentes.
DÍA 14/3
Añadiremos las fotos que corresponden con las variaciones de las lentes.
Escribiremos una breve descripción de su diseño. Que ampliaremos en la sección de productos.
DÍA 15/3
Hemos creado la pagina de contacto
hemos hecho una introducción de los objetivos que tenemos como empresa
hemos cambiado el fondo
DÍA 22/3
hemos cambiado la letra y reecho el título.
También hemos creado la página de contacto que aparece en pequeño en todas las páginas
la hemos rellenado con una breve descripción.
Nos hemos centrado en la planificación de la página de los productos.
DÍA 28/3
hemos creado los botones de suscripción que permite informar al usuario de las novedades.
Hemos puesto botones que nos reedirigen a la pagina de inicio, a la de compra y a la de contacto.
Hemos terminado de ajustar la página de inicio
DÍA 4/4
Terminaremos de hacer la subpágina de variaciones de las gafas en el inicio
Comenzaremos a hacer la página de los productos, que nos hemos planificado con anterioridad.
cambiaremos el fondo y la letra.
Añadiremos nuestro primer producto
DÍA 6/4
Iremos creando los diferentes productos.
Los ordenaremos según las categorías que hemos creado.
En cada producto individual, pondremos las opciones de color, y las de tamaño, asignaremos a dichas opciones sus fotos correspondientes.
DÍA 10/4
Seguiremos con la creación de los distintos productos
Realizaremos una breve descripción en cada uno de ellos, dónde especificaremos los grandes rasgos del producto, y las medidas correspondientes a las tallas.
Hemos terminado de poner todos los productos deseados.
DÍA 13/4
Hemos configurado la página de cada producto una vez seleccionado.
Hemos configurado la página del carrito.
Hemos configurado los métodos de pago aceptables.
Hemos configurado las regiones en las que se encuentra disponible nuestra tienda.
Hemos configurado la forma de contactar con los clientes.
Hemos comprobado la versión de la pagina en el smartphone, y la hemos ajustado.
Le damos los últimos retoques y comprobamos que cada página funcione de forma correcta.
Todas las imágenes empleadas contaban con licencias disponibles para el público.
A día de hoy, se han desarrollado un nuevo tipo de ordenadores, denominados ordenadores cuánticos, que pese a la redundancia, emplean un nuevo sistema de computación muy diferente al que estamos acostumbrados denominado como computación cuántica, que se diferencia radicalmente con la computación de un ordenador coloquial. Esta nueva forma de computación a dado mucho de que hablar últimamente, por el uso que le han dado las grandes empresas como Google o Microsoft. Debido a la complejidad del término, no se le puede atribuir una definición concreta, pero lo mas parecido sería: se trata del área de estudio centrada en el desarrollo de tecnología informática basada en los principios de la teoría cuántica, que explica la naturaleza y el comportamiento de la energía y la materia a nivel cuántico (atómico y subatómico). Anónimo ( Enero de 2019). Comenzaremos a explicar sus orígenes, evolución y características mas a fondo.
A principios del siglo XX, Planck y Einstein proponen que la luz no es una onda continua (como las ondas de un estanque) sino que está dividida en pequeños paquetes o cuantos. Esta idea, en apariencia simple, servía para resolver un problema llamado la «catástrofe ultravioleta». Pero a lo largo de los años otros físicos fueron desarrollándola y llegando a conclusiones sorprendentes sobre la materia, de las cuales interesarán dos: la superposición de estados y el entrelazamiento. Guillermo Julián (Febrero 2018)
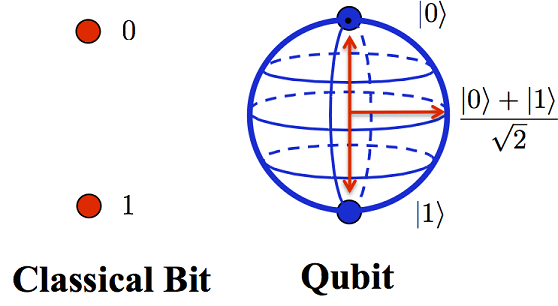
La idea de computación cuántica, como tal, surge en 1981, cuando Paul Benioff expuso su teoría para aprovechar las leyes cuánticas en el entorno de la computación. En vez de trabajar a nivel de voltajes eléctricos, se trabaja a nivel de cuanto. En la computación digital, un bit sólo puede tomar dos valores: 0 ó 1. En cambio, en la computación cuántica, intervienen las leyes de la mecánica cuántica, y la partícula puede estar en superposición coherente: puede ser 0, 1 y puede ser 0 y 1 a la vez (dos estados ortogonales de una partícula subatómica). Eso permite que se puedan realizar varias operaciones a la vez, según el número de qubits. El número de qubits indica la cantidad de bits que pueden estar en superposición. Con los bits convencionales, si teníamos un registro de tres bits, había ocho valores posibles y el registro sólo podía tomar uno de esos valores. En cambio, si tenemos un vector de tres qubits, la partícula puede tomar ocho valores distintos a la vez gracias a la superposición cuántica. Así, un vector de tres qubits permitiría un total de ocho operaciones paralelas. Como cabe esperar, el número de operaciones es exponencial con respecto al número de qubits. Para hacerse una idea del gran avance, un computador cuántico de 30 qubits equivaldría a un procesador convencional de 10 teraflops (millones de millones de operaciones en coma flotante por segundo), cuando actualmente las computadoras trabajan en el orden de gigaflops (miles de millones de operaciones). Sara Molina Cruz (Abril 2012)
Puesto que este concepto lo hemos mencionado con frecuencia, para explicar el funcionamiento de los ordenadores cuánticos, debemos entender un qubit como:
Una representación de ambos estados de una partícula sub-atómica «0» y «1» lógicos, pero de manera simultánea.
Un vector de dos qubits, representa simultáneamente, los estados 00, 01, 10 y 11
Un vector de tres qubits, representa simultáneamente, los estados 000, 001, 010, 011, 100, 101, 110, y 111
Un vector de n qubits, representa a la vez 2n estados.
Los qubits se refieren a magnitudes físicas emparejadas.Es decir, un 0 sería el fotón que oscila horizontalmente y un 1 sería el fotón que oscila verticalmente. Como veíamos antes, no sólo hay horizontal y vertical, sino que puede haber una combinación o superposición de ambas para ser usados en un sistema que sólo puede ser descrito correctamente mediante la mecánica cuántica. Anónimo 1 (fecha desconocida)
El espacio de computación de un qubit dado, es bidimensional. Ambas dimensiones se envuelven alrededor de la superficie de una esfera, y denominaremos al polo norte «cero» y al polo sur «uno». Cuando un qubit funciona, puede tomar un valor en cualquier lugar de la superficie de esa esfera. Al final del cálculo, cuando lo medimos, caerá en 0 o en 1, pero se basa probabilidad característica de la mecánica cuántica . Stephan J ( Octubre de 2019)
La interacción de los qubits con su entorno conduce al deterioro de su comportamiento cuántico y finalmente a su desaparición, esto se llama decoherencia. Su estado cuántico es extremadamente frágil. La menor vibración o variación de temperatura (las perturbaciones se denominan «ruido»), pueden hacer que los qubits caigan en un estado (dejar superposición) antes de que se realice el trabajo. Es por eso que los investigadores hacen todo lo posible para protegerlos del mundo exterior con refrigeradores súper potentes o cámaras de vacío. Stephan J ( Octubre de 2019)
Su diferencia principal con el bit convencional, es que este solo se corresponde con un único dígito del sistema de numeración binario y representa la capacidad de almacenamiento de una memoria digital. Leandro Algesa (fecha desconocida )
Un ordenador cuántico con N qubits, puede estar en una superposición cuántica arbitraria de 2 elevado a la N estados simultáneamente a diferencia de una computadora normal que solo puede estar en uno de esos 2 estados. Anónimo 1 (fecha desconocida)
Las posibilidades son infinitas porque los qubits no expresan magnitudes discretas como los bits, sino continuas. Los grupos de qubits no solo permiten albergar una infinidad de valores, sino que hacen que la capacidad de procesar información de forma simultánea crezca exponencialmente. Leandro Algesa (fecha desconocida )
DIFERENCIAS ENTRE COMPUTACIÓN CUÁNTICA Y COMPUTACIÓN CLÁSICA.
Puesto que cada proceso de qubits es totalmente independiente uno de otro, la computación cuántica puede resolver más de una operación al mismo tiempo debido al paralelismo de sus datos, por el contrario la computación clásica lo hace de forma lineal, combinación por combinación, la resolución de problemas empleando este tipo de computación es lineal. Anónimo 1 (fecha desconocida).
En la actualidad, a diferencia de la informática clásica, no existe un lenguaje computacional cuántico como tal. Los investigadores trabajan en desarrollar algoritmos (la matemática con la que trabajan también los ordenadores clásicos) que puedan dar soluciones concretas a problemas planteados. Un computador cuántico no sirve para hacer tareas cotidianas, puesto que, no cuentan con memoria o procesador. No se ha desarrollado una arquitectura tan compleja como la de un ordenador convencional. Ahora mismo son sistemas muy primitivos asimilables a una calculadora de principios del siglo pasado pero su capacidad de cálculo para determinados problemas es mucho más alta que un ordenador convencional. Anónimo 2 (Diciembre 2019).
Un computador cuántico de 30 qubits equivaldría a un procesador convencional de 10 teraflops (millones de millones de operaciones en coma flotante por segundo), cuando actualmente las computadoras trabajan en el orden de gigaflops (miles de millones de operaciones). Anónimo 3 (fecha desconocida ).
En la computación clásica se utiliza el sistema binario y en la computación cuántica se utiliza el sistema unario. Anónimo 3 (fecha desconocida ).
En un procesador cuántico no se utilizan ni monitores, ni discos duros ni ningún tipo de hardware tal y como lo conocemos hoy en día. De esta forma, todo sucede en una unidad de procesamiento que cuente con unas condiciones de absoluto aislamiento, ya que los estados cuánticos del átomo son extremadamente frágiles. Ana Muñoz de Frutos (Marzo 2017 )
PROBLEMAS A RESOLVER MEDIANTE COMPUTACIÓN CUÁNTICA.
Al igual que este nuevo sistema de computación, no es capaz de resolver los problemas del día a día, si que es capaz de la resolución de diversos problemas que se pueden llegar a dar en las grandes empresas, que son responsables de controlar y almacenar grandes cantidades de datos. Un ejemplo, lo pone Eric Ladinszky, de la compañía D-Wave, especializada en computación cuántica «Imagínese que tiene cinco minutos para encontrar un símbolo único escrito en un libro de la Biblioteca del Congreso de EE.UU. (que tiene 50 millones de libros). Eso sería imposible. Pero si estuviera en 50 millones de realidades paralelas, y en cada una de ellas pudiera hojear un libro diferente, en una de esas realidades encontrará el símbolo». Alexis Ibarra O. (fecha desconocida)
Son capaces de explorar las interacciones moleculares de un nuevo medicamento, para que se pueda llegar a poner en funcionamiento, de recibir la información de miles de millones de sensores en el mundo y con ella construir sistemas de predicción climática miles de veces más precisos o procesar rápidamente la avalancha de datos de los telescopios para encontrar exoplanetas habitables. Alexis Ibarra O. (fecha desconocida)
Una de las aplicaciones más prometedoras de las computadoras cuánticas es simular el comportamiento de la materia a nivel molecular. Fabricantes como Volkswagen y Daimler, usan computadoras cuánticas para simular la composición química de las baterías de los coches eléctricos y ayudar a encontrar nuevas formas de mejorar su rendimiento. Otras, como las farmacéuticas lo aprovechan para analizar y comparar compuestos químicos que podrían conducir a la creación de nuevos medicamentos.
Estas máquinas también son fuertes para la optimización de problemas, porque pueden manejar la información de forma extremadamente rápida a través de una gran cantidad de posibles soluciones. Airbus, por ejemplo, los utiliza para ayudar a calcular el consumo de combustible durante los ascensos y descensos para optimizarlo. Volkswagen ha presentado un servicio que calcula rutas óptimas para autobuses y taxis en las ciudades para reducir la congestión. Los investigadores también creen que las máquinas podrían usarse para acelerar la inteligencia artificial (IA).Stephan J ( Octubre de 2019)
Pueden pasar varios años antes de que la computadora cuántica alcance su máximo potencial. Las universidades y las empresas que trabajan allí, se enfrentan a una escasez real de investigadores calificados, así como de proveedores de componentes clave. Pero si estas nuevas máquinas informáticas cumplen sus promesas, podrían cambiar radicalmente las industrias y permitir la innovación. Stephan J ( Octubre de 2019)
La sociedad a día de hoy, se caracteriza por tener un vicio o enganche a las nuevas tecnologías en general, esto provoca que cada persona genere individualmente multitud de datos de manera instantánea con una simple búsqueda que en un principio parece inofensiva. Lo cierto es que dicha información queda almacena de forma permanente, al igual que todo lo que publiquemos en las redes sociales, aunque borremos esos contenidos siempre se quedan almacenados , por lo que esto solo afirma la veracidad de la popular frase «Todo lo que se publica en internet, se queda en internet.»
El data science o ciencia de los datos, es un conjunto de herramientas que permiten extraer conocimiento a partir de los datos, es la evolución de lo que hasta ahora se conocía como análisis de datos, el análisis de datos es la ciencia que se encarga de examinar un conjunto de datos con el propósito de sacar conclusiones sobre la información para poder tomar decisiones, o simplemente ampliar los conocimientos sobre diversos temas, pero a diferencia de éste que sólo se dedicaba a analizar fuentes de datos de una única fuente, el Data Scientist debe explorar y analizar datos de múltiples fuentes, a menudo inmensas (conocidas como Big Data), que pueden tener formatos muy diferentes. ( Autor desconocido 1 (fecha desconocida ))
Dentro del data science existen algunas disciplinas, puesto que el propio nombre es muy general y engloba distintos conceptos, algunas de ellas son: (Albert Obiols (Mayo del 2015))
Data Mining
El data Mining o minería de los datos, es un conjunto de técnicas y tecnologías que permiten explorar grandes bases de datos, de manera automática o semiautomática, con el objetivo de encontrar patrones repetitivos que expliquen el comportamiento de estos datos.
El objetivo de ayudar a comprender una enorme cantidad de datos, y que estos, sean utilizados para extraer conclusiones, sirven para contribuir en la mejora y crecimiento de las empresas, sobre todo, por lo que hace a las ventas o fidelización de clientes.
Su principal finalidad es explorar, mediante la utilización de distintas técnicas y tecnologías, bases de datos enormes de manera automática con el objetivo de encontrar patrones repetitivos, tendencias o reglas que expliquen el comportamiento de los datos que se han ido recopilando con el tiempo. Estos patrones pueden encontrarse utilizando estadísticas o algoritmos de búsqueda próximos a la Inteligencia Artificial y a las redes neuronales.
Las personas que se dedican al análisis de datos a través de este sistema son conocidos como mineros o exploradores de datos, estos intentan descubrir patrones en medio de enormes cantidades de datos. Su intención es la de aportar información valiosa a las empresas para así, ayudarlas en la toma de decisiones. Pero la parte que mas dificultad tiene, es la elección del logaritmo adecuado para realizar la tarea analítica concreta , puesto que existen multitud de patrones, además de tener en cuenta el propio problema a resolver, estos pueden ser la clasificación, regresión, segmentación, asociación o análisis de secuencias. Esther Ribas ( Enero, 2018 )
Los problemas a analizar son muy complejos, por ello se descompone en distintas fases, que son :
No siempre se tiene la información inmediatamente disponible en una base de datos y su obtención es parte del proceso. La recogida de la información puede realizarse mediante colocación de sensores, formularios… o de cualquier forma creativa.
Una vez se tiene la información que se considera necesaria para resolver el problema, se le debe aplicar un preprocesado. Es decir, sin perder información de valor, dar vueltas a la información que ya tenemos y prepararla para la siguiente fase. El objetivo es representar la información en un formato que consiga reducir el coste y optimizar los resultados de los algoritmos.
Hay muchas técnicas y métodos que pueden aplicarse. Algunas de ellas son:
Reducción de la dimensionalidad.
Discreción de variables.
Normalización.
Cuantificación.
Saneamiento.
El preprocesado es una fase crítica, ya que condiciona al resto del proceso y puede causar la diferencia entre el éxito y el fracaso . Por ello, esta fase y las que le proceden son tan dependientes entre sí , que lo habitual es repetir el proceso hasta encontrar la combinación mas conveniente.
Entrenar el modelo significa alimentar algoritmos de machine learning con nuestros datos.
Los algoritmos de machine learning (o aprendizaje automático) son capaces de predecir y clasificar información nueva, a raíz de haber sido entrenados con información pasada.
Algunos ejemplos de algoritmos de machine learning:
Los árboles de decisión.
Las redes neuronales.
Los algoritmos de clusterización.
Los algoritmos de machine learning se pueden clasificar como de aprendizaje supervisado o como de aprendizaje no supervisado. La diferencia es que los de aprendizaje supervisado aprenden a hallar respuestas basándose en casos pasados con sus respuestas ya conocidas, mientras que los de aprendizaje no supervisado tratan de aprender sin tener las respuestas.
Por lo general, no existe un algoritmo mejor que otro, algunos rinden mejor en unos casos , dependiendo del caso. Y la manera de hallar la mejor solución es probándolos uno a uno, con diferentes configuraciones, hasta encontrar el mejor para nuestro caso. Se sigue una metodología experimental prueba-error . Solo los mejores profesionales en machine learning pueden tener una vaga idea de qué tipo de algoritmos pueden funcionar mejor con un set de datos determinado. Pero aún así tendrían que probar varias opciones y testearlas.
Existen diferentes técnicas para validar los resultados de un algoritmo de machine learning, es decir, para medir la bondad del clasificador. Para los de aprendizaje supervisado, entre otras técnicas, se reserva una parte de los datos para realizar el entrenamiento y el resto se utiliza para validar o testear el modelo. Para los de aprendizaje no supervisado es más complicado, pero también existen métodos que dan una estimación de la bondad del algoritmo.
A veces incluso lo que más conviene es elegir aplicar varios algoritmos a la vez y dar por buena la respuesta más votada entre los algoritmos elegidos.
Finalmente, para poder comunicarlo a terceros, se tiene que representar de alguna forma el conocimiento obtenido. Se tiene que hallar la manera más limpia e intuitiva de visualizar los resultados y, con ayuda de diferentes softwares, crear estas visualizaciones.
Ainhoa Lafuente (fecha desconocida).
BIG DATA
Cuando hablamos de Big Data nos referimos a conjuntos de datos o combinaciones de conjuntos de datos cuyo tamaño (volumen), complejidad (variabilidad) y velocidad de crecimiento (velocidad) .Esto se conoce como las 3 V’s. Estos datos, dificultan su gestión, procesamiento o análisis mediante tecnologías y herramientas convencionales, tales como las bases de datos relacionales y estadísticas convencionales o paquetes de visualización, dentro del tiempo necesario para que sean útiles.
Dicho de otra forma, el big data, está formado por conjuntos de datos de mayor tamaño y mayor complejidad, especialmente procedentes de nuevas fuentes de datos. Estos conjuntos de datos son tan voluminosos que el software de procesamiento de datos convencional sencillamente no puede gestionarlos. Sin embargo, estos volúmenes masivos de datos pueden utilizarse para abordar problemas empresariales que antes no hubiera sido posible solucionar. Por lo que ha supuesto un gran avance para las empresas de hoy en día. Autor desconocido 3 (fecha desconocida)
A continuación explicaremos el concepto de las 3 V’s que son las que conforman el big data:
Volumen
La cantidad de datos importa. Con big data, se procesan grandes volúmenes de datos no estructurados de baja densidad. Puede tratarse de datos de valor desconocido, flujos de clics de una página web o aplicaciones móviles, o de un equipo con sensores. Para algunas organizaciones, esto puede suponer decenas de terabytes de datos, o incluso petabytes.
Velocidad
La velocidad es el ritmo al que se reciben los datos y al que se aplica alguna acción. La velocidad máxima de los datos normalmente se transmite directamente a la memoria, en vez de a un disco. Algunos productos inteligentes habilitados para Internet funcionan en tiempo real o prácticamente en tiempo real y requieren una evaluación y actuación en tiempo real.
Variedad
La variedad hace referencia a los diversos tipos de datos disponibles. Los tipos de datos convencionales eran estructurados y podían organizarse claramente en una base de datos convencional. Con el auge del big data, se presentan en nuevos tipos de datos no estructurados. Los tipos de datos no estructurados y los semiestructurados, como el texto, audio o vídeo, los cuales requieren un preprocesamiento adicional para poder obtener significado y habilitación.
Autor desconocido 2 (fecha desconocida).
En los últimos años, han surgido otras «dos V»: valor y veracidad.
Los datos poseen un valor intrínseco. Sin embargo, no tienen ninguna utilidad hasta que dicho valor se descubre. Resulta igualmente importante: ¿cuál es la veracidad de sus datos y cuánto puede confiar en ellos?
Hoy en día, el big data se ha convertido en un activo crucial. Pensando en algunas de las mayores empresas tecnológicas del mundo, se sabe, que gran parte del valor que ofrecen procede de sus datos, que analizan constantemente para generar una mayor eficiencia y desarrollar nuevos productos, que se adapten mejor a los gustos de los consumidores.
Los avances tecnológicos que han ido surgiendo recientemente, han conseguido reducir exponencialmente el coste de almacenamiento y computación de datos, haciendo que almacenar datos resulte más fácil y barato. Actualmente, con un mayor volumen de big data más barato y accesible, puede tomar decisiones empresariales más acertadas y precisas.
DATA ANALYTICS
El término data analytics o big data analytics, es una de las variantes del Big Data, pero aplicado en el ámbito empresarial o en instituciones públicas mayormente, es el análisis cantidades desmesuradas de datos, los cuales las empresas se dedican a almacenar, analizar y cruzar dicha información para intentar encontrar patrones de comportamiento en los individuos y en la sociedad como colectivo, dando así una idea a las empresas de que solicitan o carecen los consumidores, para darles dicho servicio.
Para aclarar conceptos, el data analytics, es un conjunto de sistemas, que unidos a una gran capacidad de conceptos matemáticos, son capaces de analizar los datos que generamos diariamente, y le dan un significado para las instituciones.
Existen varios tipos de data analytics, puesto que cada uno de ellos se encarga de una función específica en el sistema. Y son :
Descriptivo
Explica con la ayuda de los datos y mediante gráficos o informes, las necesidades de la población en el pasado, pero no sirve para predecir las necesidades futuras. Sólo aporta una idea a las empresas de la evolución de los requerimientos sociales.
Diagnóstico
Se realiza una fusión el anterior, con el descriptivo, y juntos, intentan hallar la razón de los datos anteriores y el motivo por el que ocurrieron de dicha forma .
Predictivo
El mas útil y empleado por las empresas. Se encarga de analizar los datos para predecir los cambios que podrían suceder en la sociedad a lo largo de un tiempo. Esto les permite una mayor adaptabilidad a dichos cambios, puesto que si las predicciones son acertadas, las empresas solo saldrían beneficiadas.
Prescriptivo
Es una evolución del anterior, basado en procesos de automatización o AB testing. Este sistema no solo analiza los dato y los predice, si no que también aconseja como se debe proceder a partir de los obtenidos, recomendando rutas o localizaciones, para evitar el tráfico, por ejemplo. Acciona (Marzo 2017)
Big Data Analytics trae consigo un abanico de conceptos digitales que serán cada vez más familiares, como el de los data lakes, el repositorio donde la información en bruto espera a ser analizada, o los de la minería de datos y el aprendizaje automático. Estos últimos son sistemas que buscan patrones cruzando la información, pero con una diferencia sustancial entre ellos. Si la minería de datos extrae la información para que una persona la analice, el aprendizaje automático va un paso más allá: detecta los patrones y actúa en consecuencia.
Un caso muy claro que lo ilustra es el feed de Facebook. La red social va aprendiendo de nuestras interacciones y ajusta nuestro muro a esa pauta de comportamiento ofreciéndonos más contenidos que cree pueden ser de nuestro agrado. Por eso, la inteligencia artificial tendrá cada vez más protagonismo en el Big Data. Ya no solo importa que el análisis de las herramientas sea eficiente, sino que además lo hagan en tiempo real e incluso puedan aprender los patrones y predecirlos. Autor desconocido 4 ( 15 de septiembre )
BUISINESS INTELIGENCE
Podemos definir Business Intelligence como el conjunto de metodologías, aplicaciones y tecnologías que permiten reunir, depurar y transformar datos de los sistemas transaccionales e información desestructurada en información estructurada, para su explotación directa o para su análisis y conversión en conocimiento, dando así soporte a la toma de decisiones sobre el negocio.
La inteligencia de negocio actúa como un factor estratégico para una empresa u organización, generando una potencial ventaja competitiva, que no es otra que proporcionar información privilegiada para responder a los problemas de negocio: entrada a nuevos mercados, promociones u ofertas de productos, eliminación de islas de información, control financiero, optimización de costes, planificación de la producción, análisis de perfiles de clientes, rentabilidad de un producto concreto, etc… .Media (octubre 2017)
Los principales productos de Business Intelligence que existen hoy en día son:
Cuadros de Mando Integrales (CMI)
Sistemas de Soporte a la Decisión (DSS)
Sistemas de Información Ejecutiva (EIS)
Los sistemas y componentes del BI se diferencian de los sistemas operacionales en que están optimizados para preguntar y divulgar sobre datos. Esto significa que, en un los datos están desnormalizados para apoyar consultas de alto rendimiento, mientras que en los sistemas operacionales suelen encontrarse normalizados para apoyar operaciones continuas de inserción, modificación y borrado de datos. En este sentido, los procesos (extracción, transformación y carga), que nutren los sistemas BI, tienen que traducir de uno o varios sistemas operacionales normalizados e independientes a un único sistema que se encuentra desnormalizado, cuyos datos están completamente integrados.
Una solución BI completa, a un problema, permite:
Observar ¿qué está ocurriendo?, Comprender ¿por qué ocurre?, Predecir ¿qué ocurriría?, Colaborar ¿qué debería hacer el equipo?, y Decidir ¿qué camino se debe seguir?
Este sistema está relacionado directamente con el Big Data, pero lo cierto es que existen diferencias entre ellos. Algunas de sus características mas notables son:
BI es una forma sistemática para las empresas de lanzar preguntas y obtener respuestas útiles de sus sistemas de información, ya que se basa en el conocimiento acumulado del negocio.
Pero, en cambio, Big Data permite mirar hacia el futuro y enfocarse en detalles que, a primera vista podrían parecer menos relevantes, aunque terminan demostrando ser fuente de grandes oportunidades. Claro está que, para ello es preciso llevar a cabo un análisis que en algunos casos, sólo está al alcance de personal técnico especializado. A diferencia de los requisitos que impone BI, mucho menos exigentes, que democratizan el conocimiento en la organización, al ponerlo en manos de todos los usuarios del negocio. Redacción APD (Marzo de 2019)
MACHINE LEARNING
El Aprendizaje Automático o Machine Learning, consiste en una disciplina de las ciencias informáticas, relacionada con el desarrollo de la Inteligencia Artificial, y que sirve, para crear sistemas que pueden aprender por sí solos.
Es una tecnología que permite hacer automáticas una serie de operaciones con el fin de reducir la necesidad de que intervengan los seres humanos. Esto puede suponer una gran ventaja a la hora de controlar una ingente cantidad de información de un modo mucho más efectivo.
Debemos entender el término aprendizaje como la capacidad del sistema para identificar una gran serie de patrones complejos determinados por una gran cantidad de parámetros, es decir, la máquina no aprende por sí misma, sino por un algoritmo de su programación, que se modifica con la constante entrada de datos en la interfaz, y que puede predecir escenarios futuros o tomar acciones de manera automática según ciertas condiciones. Como estas acciones se realizan de manera autónoma por el sistema, se dice que el aprendizaje es automático, sin intervención humana. Sinnexus (fecha desconocida)
Un sistema informático de Aprendizaje Automático se sirve de experiencias y evidencias en forma de datos, con los que comprender por sí mismo patrones o comportamientos. De este modo, puede elaborar predicciones de escenarios o iniciar operaciones que son la solución para una tarea específica.
A partir de un gran número de ejemplos de una situación, puede elaborarse un modelo que puede deducir y generalizar un comportamiento ya observado, y a partir de él realizar predicciones para casos totalmente nuevos. Como ejemplo, se puede considerar la predicción del valor de unas acciones en el futuro según el comportamiento de las mismas en periodos anteriores.
El machine learning, y su uso tan complejo de algoritmos marcará en un futuro próximo, la competitividad y la profesionalidad entre las distintas empresas, puesto a la mejora de sus servicios y productos, tanto para los procesos de sus organizaciones propios, como la mejora de la experiencia en el trabajo y el entretenimiento de sus clientes. Autor desconocido 5 (noviembre 2019)
CONCLUSIÓN
En definitiva todos los conceptos de los que hemos hablado con anterioridad, tienen algún tipo de relación entre ellos, puesto que la mayoría son una derivación de otro concepto con ciertas modificaciones, pero que al fin y al cabo ambos tienen el mismo origen, si bien es cierto que las diferencias que los caracterizan pueden suponer que a un empresa, por ejemplo, le venga mejor el empleo de un método que el de otro , puestos que dichas peculiaridades hacen único al sistema.
BIBLIOGRAFÍA
¿Qué es un data scientist? Albert Obiols (Mayo del 2015) https://inlab.fib.upc.edu/es/blog/que-es-un-data-scientist
Internet a día de hoy, es uno de los métodos, por no decir, el método de búsqueda de información preferente por los usuarios . Internet se ha convertido en una herramienta necesaria en nuestras actividades diarias, y incluso sin ella estaríamos perdidos en muchas ocasiones, puesto que las generaciones a partir del 2000 y anteriores, no conocen una vida sin la facilidad de buscar algo al alcance de su mano, desde lo que puede ser, una ubicación concreta de una calle a la que se quiere llegar, hasta buscar el nombre científico de una especie, la información a encontrar es ilimitada. Como hemos observado el método de búsqueda ha evolucionado a pasos agigantados a lo largo de los años, desde buscar el significado de una palabra en un diccionario de 500 hojas, hasta buscar en un dispositivo concreto «definición de celeridad», y obtener los resultados en relativamente 0,5 mili segundos, lo que nos ha supuesto un inmenso recorte de nuestro tiempo , puesto que en lo que se tardaba 2 horas antiguamente, ahora se obtiene de forma instantánea.
¿Qué es Internet?
Internet es una red de telecomunicaciones que utiliza líneas telefónicas, cables, satélites y conexiones inalámbricas para conectar computadoras y otros dispositivos a la World Wide Web. Todas las computadoras modernas pueden conectarse a Internet, al igual que algunos televisores, consolas de videojuegos y otros dispositivos. Hugo Delgado (Agosto del 2019)
A diferencia de los servicios en línea, que son controlados centralmente, Internet está descentralizada. Cada computadora de Internet, llamada host, es independiente. Los operadores pueden elegir qué servicios de Internet usar y qué servicios locales poner a disposición de la comunidad global. Notablemente, esta anarquía por diseño funciona extremadamente bien. Hay una variedad de formas de acceder a Internet. La mayoría de los servicios en línea ofrecen acceso a algunos servicios de Internet. También es posible obtener acceso a través de un proveedor de servicios de Internet (ISP) comercial.
A diferencia de los servicios en línea, que son controlados centralmente, Internet está descentralizada. Cada computadora de Internet, llamada host, es independiente. Los operadores pueden elegir qué servicios de Internet usar y qué servicios locales poner a disposición de la comunidad global. Notablemente, esta anarquía por diseño funciona extremadamente bien. Hay una variedad de formas de acceder a Internet. La mayoría de los servicios en línea ofrecen acceso a algunos servicios de Internet. También es posible obtener acceso a través de un proveedor de servicios de Internet (ISP) comercial.
A diferencia de los servicios en línea, que son controlados centralizados, Internet es una red que se encuentra descentralizada. Cada dispositivo que se conecta a Internet, se denomina host, y son independientes unos de otros. Los operadores que ofrecen el servicio de conectarse a la red, pueden elegir qué servicios de Internet usar y qué servicios locales poner a disposición de la comunidad global. Hay una variedad de formas de acceder a Internet, la mayoría de los servicios en línea ofrecen acceso a algunos servicios de Internet. También es posible obtener acceso a través de un proveedor de servicios de Internet (ISP) comercial.
Internet no es sinónimo de World Wide Web. Internet es una red masiva de redes, una infraestructura de redes. Conecta millones de computadoras en forma global, formando una red en la que cualquier computadora puede comunicarse con cualquier otra computadora siempre y cuando ambas estén conectadas a Internet. La World Wide Web, o simplemente la Web, es una forma de acceder a la información a través de Internet. Es un modelo de intercambio de información que se construye sobre Internet. Hugo Delgado (Octubre del 2019).
Evolución de la web.
Cómo es lógico a lo largo de la historia el funcionamiento y el uso de Internet ha ido cambiando y evolucionando a la vez que lo hacía la sociedad, debido a esto podemos afirmar que esta red se ha ido transformando, desde su nacimiento, según las necesidades y requisitos de la sociedad del momento .
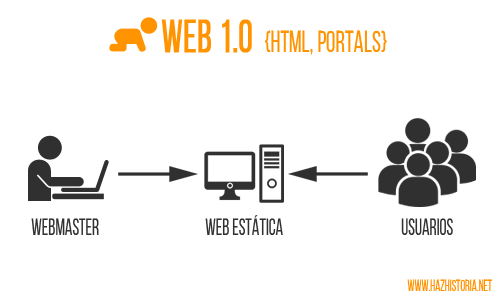
Web 1.0
En 1991 se publica la primera página web creada por Tim Berners-Lee usando un computador NeXT. Se hablaba sobre el emergente y emocionante mundo del World Wide Web.
La web primitiva, la del siglo 20, era aquella que se caracteriza principalmente por ser unidireccional y realizada sobre contenidos estáticos principalmente HTML, donde abundaba el uso de marcos y botones gif . Las primeras páginas que vimos en Internet publicaban contenidos de texto que, una vez publicados, no se actualizaban salvo que el «webmaster» modificase dichos contenidos y volviese a subir la web de nuevo a internet.
La web 1.0 tenía un carácter principalmente divulgativo, y empezaron a colgarse en internet documentos e información principalmente cultural. Poco a poco las empresas empezaron a tomar parte y las primeras webs de empresa surgieron, con diseños muy pobres (no había herramientas, ni tecnología, ni conexión suficiente como para hacerlo mejor) y contenidos que rápidamente quedaban anticuados al ser complejo actualizarlos.
El consumidor tenía un papel pasivo donde sólo recibía información de las empresas. Los usuarios solamente podían interactuar a través de e-mail, chat o en los hilos de conversación de los primeros foros de internet. Anónimo (fecha desconocida)
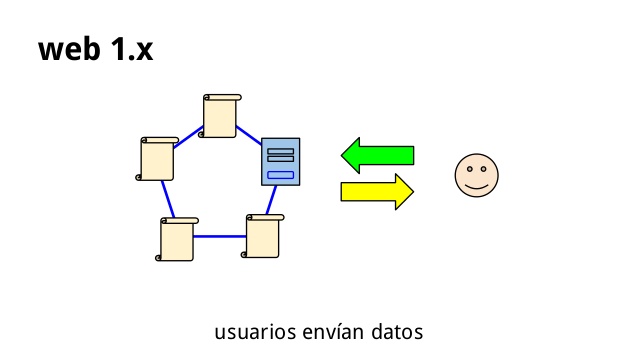
Web 1.X
Creo que es conveniente hablar de un estado avanzado de la Web 1.0 que evoluciona por un camino diferente. La web 1.X es una web, al igual que su antecesora, también unidireccional, pero en comparación con la anterior, dinámica, que propone al administrador herramientas para manipular los contenidos sin que éste tenga conocimientos de programación o Internet. Romero Domínguez (fecha desconocida).
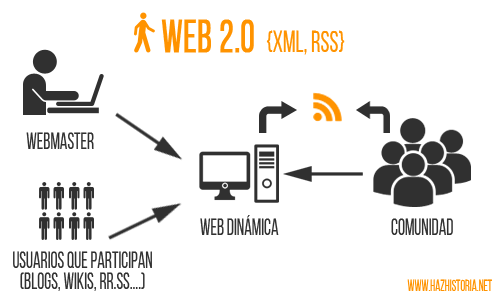
La web 2.0 se asienta aproximadamente, a mediados de la primera década de este siglo. Sustentada bajo unas conexiones a internet ya evolucionadas (ya teníamos ADSL), y mejores herramientas para desarrollar web, mejores servidores, etc., la web 2.0, también denominada como «la red social»,se encuentra llena de contenidos en formato de blogs, wikis, foros y finalmente, se da con el inicio de las redes sociales. El objetivo de la web 2.0 es la compartición de conocimientos o de ideas, por decirlo así, es una web colaborativa, y esta característica ha sido uno de los principales atractivos que ha conseguido captar a los usuarios del momento (basta ver el porcentaje de los usuarios de facebook que, hasta la llegada de facebook, no habían tocado un ordenador). Anónimo (fecha desconocida)
Este tipo de web tenía dos funciones principalmente:
La fidelizaciónde usuarios: La fidelización de usuarios es posible al contar con uno de los posibles enfoques el centrarse en la aportación de contenidos por parte de los usuarios, y la facilitación de la comunicación entre visitantes y administrador, o bien incluso entre los propios usuarios.
La naturaleza que tienen las páginas web 2.0 logra animar, bien sea de manera automática, o bien sea a través de campañas de comunicación, a que los visitantes regresen nuevamente y finalmente terminen por convertirse en usuarios. Además, logra generar una mayor confianza, ya que no brinda únicamente contenidos que hayan sido publicados por el administrador.
Promoción social Como buen ejemplo de la web 2.0 llevada a su límite, nos encontramos con las redes sociales y los contenidos sociales. Dichas páginas se suelen basarse principalmente de las diferentes aportaciones que llevan a cabo los usuarios.
Día a día, año tras año, resulta cada vez más relevante todo aquello que se diga en estas páginas, y ello es porque aquello que se publique en ellas, de manera automática, quedará a la completa disposición de los diferentes contactos de cada usuario en cuestión.
En aquellos casos en los que alguno de los contactos del usuario lo consideren interesante, también lo compartirá. De modo que se hace más que evidente el gran beneficio que se puede lograrse en aquellos aspectos promocionales que se llevan a través de la red.
Si bien es cierto que las ventajas que ofrece la web 2.0 no termina aquí y van mucho más lejos, hay que señalar que son los principales beneficios que brindan, las principales utilidades que se puede hacer de ella. José Peinado (Junio de 2017 ).
Web 3.0
La web 3.0 es la web semántica, la web de la nube, la web de las aplicaciones y la web multidispositivo. Los usuarios y los equipos, en este marco, pueden interactuar con la red mediante un lenguaje natural, interpretado por el software. A día de hoy ya no solamente utilizamos ordenadores para conectarnos a Internet, también conseguimos conectar televisores etc. En un futuro no muy lejano, todo lo que no esta conectado actualmente se verá conectado a Internet de una forma u otra, como el sector automovilístico.
La web 3.0 se presenta como una web inteligente, y principalmente aprovecha la nube para prestar servicios al usuario y eliminar su necesidad de disponer de sistemas operativos complejos y grandes discos duros para almacenar su información, facilitándole así la manera de almacenar la información. Anónimo (fecha desconocida).
El principal objetivo de esta web es es el desarrollo de aplicaciones que permitan que los consumidores puedan capturar, gestionar, buscar e interaccionar con contenidos y servicios de forma fácil, segura y personalizada, combinando las herramientas de la Web semántica (Web 1.0) con las tecnologías de la Web social (Web 2.0) sobre la base del nuevo concepto de la Web 3.0. Anónimo (Agosto 2015).
La Web 4.0 propone un nuevo modelo de interacción con el usuario más completo y personalizado, no limitándose simplemente a mostrar información, sino comportándose como un espejo mágico que dé soluciones concretas a las necesidades del navegante.
Web 4.0 es una capa de integración necesaria para la explotación de la Web semántica y sus enormes posibilidades,que a día de hoy no se encuentra en funcionamiento pero en un futuro próximo si lo estará. Es un nuevo modelo de Internet que nace con el objetivo de resolver las limitaciones de la red a día de hoy. Con este nuevo modelo de Web podremos hacer consultas del tipo “Quiero comida a domicilio ” y que tu móvil se comunique automáticamente con la compañía de restaurantes que realicen entregas a domicilio, más cercana, sin intervención directa del usuario. Anónimo (2012)
El principal objetivo de este tipo de web es la inteligencia artificial, definido como en el entorno científico de computación, una máquina «inteligente» es un agente racional flexible que percibe su entorno y lleva a cabo acciones que maximicen sus posibilidades de éxito en algún objetivo o tarea. Actualmente el término «inteligencia artificial» se aplica cuando una máquina limita las funciones «cognitivas» que los humanos asocian con otras mentes humanas, como por ejemplo: aprender y resolver problemas. Ivette Fuentes (fecha desconocida).
Las aplicaciones en internet son un conjunto de programas diseñados para la realización de una tarea concreta, como una aplicación comercial, contable, etc. Actualmente las aplicaciones en internet son de lo más utilizado en la web debido a la gran versatilidad y facilidad de consulta por parte de los usuarios cada día se incrementa en la red más grande de todo el mundo que es internet.• Estas aplicaciones en internet pueden ser aplicaciones en flash, en asp, php, html, photoshop, DHTML , JAVA, JAVASCRIPT, entre otros. martincaicedoc (Mayo 2012 )
Algunos de las aplicaciones mas empleadas a día de hoy :
Google Maps: es un servicio de mapas al que se accede desde un navegador web. Dependiendo de la ubicación geográfica, se pueden ver mapas básicos o personalizados e información sobre negocios locales, como su ubicación, datos de contacto, su ubicación e indicaciones sobre cómo llegar hasta ellos. Personalmente es una de las aplicaciones en línea que mas empleo, puesto que si no se llegar a alguna dirección, es tan fácil como introducir la dirección, en mi teléfono y guiarme hasta el destino, bien sea en un vehículo o a pie.
Por supuesto las redes sociales, son las aplicaciones en línea mas empleadas de la historia, puesto que es la nueva forma que tenemos de conectarnos con otros usuarios conocidos que se encuentran en otro país, o simplemente comunicarnos, entretenernos y compartir nuestro día a día con los seguidores. Algunos ejemplos de redes sociales son:
WhatsApp : No es sorprendente que se haya convertido en una de las redes mas populares, puesto que a día de hoy se ha convertido en uno de nuestros medios de comunicación favoritos. Con respecto a los datos de 2017, el panorama ha cambiado poco, ya que pasa de ser usada por un 70% de los usuarios a un 74%. Cada vez mayor parte de la población tiene esta aplicación, es la más efectiva para contactar con tus amigos o familiares sin realizar una llamada telefónica.
Instagram: Al igual que WhatsApp se ha convertido en una de las aplicaciones mas usadas por los usuarios mas jóvenes junto con Twitter, puesto que es una forma de entretenimiento sencilla, que se basa en compartir el día a día de las personas. Muchas de ellas aprovechándose de esto se han convertido en personas con una amplia red de seguidores, que acaban ganando una amortización por el contenido subido y compartido con sus followers.
Facebook : Desde su creación, fue muy popular, pero si que es cierto que a lo largo de los años, con la aparición de nuevas redes sociales, su popularidad ha ido disminuyendo de manera continua. Aunque ciertamente sigue siendo la red mas popular seguida de instagram.
Para subir contenidos etc, estas son las aplicaciones web mas usadas, pero a su vez para el almacenamiento en la nube de la información , se emplea otras aplicaciones distintas como por ejemplo : Google Drive, es un servicio proporcionado por google que nos permite almacenar datos en la nube, a través de nuestro correo electrónico de una cuenta google. La gran ventaja de este servicio, es que la información se encuentra disponible en cualquier tipo de dispositivo, simplemente ha de ingresarse el correo dónde esta guardada dicha información.
Para producir dicho contenido que subimos a la red, empleamos aplicaciones web como por ejemplo: OppenOffice, este nos permite la creación ilimitada, en cuanto a palabras de un documento se refiere, de contenido que posteriormente podemos publicar en un blog, o similares.
Para la organización de la información, también se pueden emplear aplicaciones , que sin lugar a duda facilitan el método de planificación del contenido de cada usuario, aplicaciones como Flipboard son muy útiles.
Nos hemos decantado por la explicación de dichas aplicaciones, puesto que consideramos que su practicidad es evidente, y son las aplicaciones mas comunes y útiles que realizan su función de forma adecuada en su ámbito propio.
Aunque se piense que únicamente los proyectos mas populares, que ganan mayor fama sean los únicos que tengan derechos de autor, bien sean películas o música, estamos muy equivocados. Puesto que, todo lo que se publica en Internet, a parte de ser creado por una persona concreta, o autor, también tiene ciertos limites para su empleo y difusión. A día de hoy, este concepto no está totalmente aceptado por la sociedad, puesto que se tiene la creencia de que si ese contenido está en internet es de uso público, cuando este concepto es totalmente erróneo. Debido a que multitud de personas emplean las ideas que encuentran por la plataforma, es habitual escuchar en multitud de artículos periodísticos , el robo ,por ejemplo, de un artista a otro en el ritmo de una canción concreta , o como una instagramer o influencer ha robado una foto que tenía derechos reservados a otra .
Para evitar que nuestro contenido se veo desprotegido y usado por otras personas como propio , comienza a surgir la idea de las licencias. Cuando hablamos de licencia en el mundo digital nos referimos a la autorización que el autor de un contenido da a otras personas sobre lo que pueden o no pueden hacer con dicha información. Existen diversas licencias, que dependiendo del sujeto , se adaptarán de mejor manera a los gustos del consumidor.
Con el copyright, nos referimos a todos los derechos reservados. Es la licencia más empleada, especialmente por empresas y autores de importancia,esto a su vez, implica que solamente su autor puede utilizar, modificar y distribuir su contenido. Si alguien mas quiere realizar alguna modificación sobre él, necesita la autorización expresa del autor, en muchos casos, el pago por su uso. Cualquier contenido disponible en Internet que no especifique un tipo de licencia, está automáticamente protegido por Copyright, aunque pueden utilizarse, con fines educativos o noticiarios.
El derecho de autor es un conjunto de normas jurídicas y principios que afirman los derechos morales y patrimoniales que la ley concede a los autores, solo por el hecho de la creación de una obra literaria, artística, musical, científica o didáctica, que esté publicada.
El concepto de derechos de autor se aplica a las distintas normativas que rigen sobre la acción creativa de cualquier tipo que implica que alguien al crear o ser el autor de algo (un libro, un aparato electrónico, una idea incluso) posee el derecho a ser reconocido como el único autor de modo tal de que nadie más pueda usurpar los beneficios económicos o intelectuales que salgan de esa actividad.
COPYLEFT
El copyleft es un método para convertir un programa en software libre y exigir que todas las versiones del mismo, modificadas o ampliadas, también lo sean. Esta licencia ofrece la posibilidad de usar, copiar y redistribuir una obra y sus versiones derivadas simplemente reconociendo su autoría. No exige autorización del autor para su uso.
La forma más sencilla de hacer que un programa sea libre es ponerlo en el dominio público, sin derechos reservados. Esto permite a la gente compartir el programa, así como sus mejoras, si así lo desean. Pero asimismo permite, a quienes no crean en la cooperación, convertir el programa en software propietario. Pueden hacer cambios, muchos o pocos, y distribuir su resultado como un producto propietario. Pero la condición implantada al utilizar esta licencia, es que cualquiera que distribuya software, con o sin modificaciones, debe traspasar con él la libertad para copiarlo y modificarlo. El copyleft garantiza que cada usuario goce de la libertad de interacción con dicha información.
La palabra «copyleft» comenzó a utilizarse en los años setenta por oposición a copyright para señalar la libertad de difusión de determinados programas informáticos que les otorgaban sus creadores. Unos años más tarde se convirtió en un concepto clave del denominado software libre, que Richard Stallman plasmó en 1984 en la General Public License (GPL, «licencia pública general»).A partir de Copyleft nacen otros tipos de licencias para la distribución de contenidos digitales en la Red. Entre los más populares destaca Creative Commons (CC), y GLP como ya hemos mencionado con anterioridad.
Es una organización no gubernamental, creada en el año 2001 por Lawrence Lessig , desarrolla planes para ayudar a eliminar o reducir las barreras legales de la creatividad a través de nuevas leyes y nuevas tecnologías.
Creative Commons (traducido como “bienes comunes creativos )” o CC están inspiradas en la licencia GPL (General Public License) de la Free Software Foundation, compartiendo buena parte de sus principios. La idea principal detrás de ellas es posibilitar un modelo legal ayudado por herramientas informáticas para así facilitar la distribución y el uso de contenidos.
Las licencias se basan en la propiedad intelectual. Sin derechos de propiedad intelectual no serían necesarias, ya que el autor no debería autorizar nada porque no tendría reconocido ningún derecho.
Para poder licenciar una obra bajo Creative Commons, lo principal es ser el autor y el titular de los derechos. Puede ser autor y no titular si los ha cedido; en este caso, no puede asignar una licencia, sino que debería pedir permiso al nuevo titular.
Existe una serie de licencias Creative Commons, cada una con diferentes configuraciones, que permite a los autores poder decidir la manera en la que su obra va a circular en la red, entregando libertad para citar, reproducir, crear obras derivadas y enseñarlas públicamente bajo ciertas diferentes restricciones, y son:
1.-Reconocimiento (by) Se permite cualquier explotación de la obra, incluyendo una finalidad comercial, así como la creación de obras derivadas, la distribución de las cuales también está permitida sin ninguna restricción.
2.- Reconocimiento – NoComercial (by-nc) Se permite la generación de obras derivadas siempre que no se haga un uso comercial. Tampoco se puede utilizar la obra original con finalidades comerciales.
3.- Reconocimiento – NoComercial – CompartirIgual (by-nc-sa) No se permite un uso comercial de la obra original ni de las posibles obras derivadas, la distribución de las cuales se debe hacer con una licencia igual a la que regula la obra original.
4.- Reconocimiento –No Comercial – Sin Obra Derivada (by-nc-nd) No se permite un uso comercial de la obra original ni la generación de obras derivadas.
5.- Reconocimiento –Compartir Igual (by-sa) Se permite el uso comercial de la obra y de las posibles obras derivadas, la distribución de las cuales se debe hacer con una licencia igual a la que está regulada la obra original.
6.- Reconocimiento –Sin Obra Derivada (by-nd) Se permite el uso comercial de la obra, pero no la generación de obras derivadas.
GNU GPL
Las licencias GNU GPL o General Public License, es una licencia copyleft, creada por la empresa Free Software Foundation en los años 80, creadas con el fin de proteger la libre distribución, uso y modificación del software . Cualquier programa que utilice este tipo de licencias se declara como de software libre . Sobre esta licencia se han desarrollado plataformas de comercio electrónico, cuyas finalidades están dirigidas a distintos sectores, como puede ser : al ámbito comercial con la licencia OSCommerce; La licencia de Arte Libre (LAL) para obras artísticas; ColorIURIS, creada por un español, se trata de un sistema mixto entre la autogestión y la cesión de derechos de autor. Pero destaca su uso en el ámbito de programas informáticos, los dos ejemplos más conocidos que emplean este tipo de licencia son Ubuntu y OpenOffice , puesto que que cualquier persona puede instalar el programa en cuestión, modificar su código o distribuirlo sin autorización expresa del autor. Esta licencia, tiene validez legal mundial.
Fuente : autor desconocido , fecha de publicación 29 de Junio de 2007 . gnu.org/licenses/gpl-3.0.html
LGPL
LGPL (GNU Lesser General Public License en español Licencia Pública General Reducida de GNU) es una licencia de software libre publicada por la Free Software Foundation. LGPL es una alternativa más permisiva que la licencia copyleft GPL.
Esto supone que cualquier trabajo que use un elemento con licencia GPL tiene la obligación de ser publicado bajo las mismas condiciones (libre de usar, compartir, estudiar, y modificar). Por otro lado, LGPL solo requiere que los componentes derivados del elemento bajo LGPL sigan con esta licencia, y no es necesario que sea el programa al completo.
LGPL es usado habitualmente para licencias de componentes compartidos como por ejemplo librerías (.dll, .so, .jar, etc.).
El Iot, Internet of things, o traducido, como el Internet de las cosas, se puede decir que es la consolidación de redes a través de una red, que contiene gran variedad de objetos físicos, bien sean vehículos, máquinas, electrodomésticos o incluso objetos no tecnológicos, que se conectan entre sí por medio de esta, para intercambiar datos o información, por medio de sensores o API’s (interfaces de programación de aplicaciones).
Las IOT hoy en día cobran un gran importancia, y puesto que nos encontramos en la era de mayor desarrollo tecnológico, nunca visto, estas se emplean en numerosos sectores, tales como en la hostelería, actualmente en muchos establecimientos de comida rápida, se indica a través de un terminal si el plato está preparado, incluso los camareros pueden saber en la mesa que tienen que servir dicho plato. Incluso en los grandes almacenes de comida se emplea el Internet de las cosas, puesto que los alimentos están categorizados e introducidos en una red interna, en la cuál se indica la fecha de caducidad de los productos, la gestión de los electrodomésticos, la temperatura de las cámaras frigoríficas, o la temperatura de los hornos etc.
Figura 1
A su vez la utilización de las Iot se ha convertido en el recurso principal de las grandes empresas comerciales , que se encuentran de cara al público, puesto que al realizar una búsqueda en Internet todos nuestros datos quedan recopilados . Estos datos son de gran valor para los distintos comercios, puesto que efectúan un análisis de las ventas de los productos para saber los gustos de los consumidores, que productos no se venden y el por que. Se hace especial hincapié en concreto en los centros comerciales, aunque los consumidores no lo noten, se recopilan millones de datos, con los que se elaboran distintas estadísticas, que contestan a preguntas como ¿Dónde invierte en cliente mas tiempo?, ¿Qué compra?, ¿A que hora hay mayor fluencia de personas?. Los centros comerciales, lugar donde trabajan grandes vendedores, saben que la información es dinero, y por eso se estudian las ofertas, la colocación de los productos, el diseño de los paneles, etcétera, basándose en todos los datos que están a su alcance y que son capaces de obtener en sus instalaciones. Toda esa información es útil para generar el mejor catálogo de productos, y poner el descuento en el sitio adecuado, a la hora adecuada, el día adecuado y conseguir maximizar sus ganancias.
Figura 2
Figura 3
Para efectuar estos estudios, se emplean varios métodos: El más típico son las cámaras de seguridad que cuentas con reconocimientos faciales, que se instalan en cada rincón, pero a día de hoy, se prefiere emplear un método mucho mas simple y eficaz, el smartphone, puesto que estamos en la era que estamos, se ha convertido en un elemento esencial en nuestras vidas, tanto que si no lo tenemos cerca, nos crea la ansiedad de estar incomunicados, nos referimos a este problema como nomofobia . Aprovechándose de esto, los grandes establecimientos como los centros comerciales, saben que dónde vayamos nosotros va nuestro teléfono, por lo que ubicación de nuestros dispositivos y la información que transmitimos a partir de la redes wifi o bluethoot ayudan a la extracción de datos que completan sus encuestas.
Existen numerosos tipos de servicios, que ayudan a las distintas empresas a saber su fluencia de clientes etc, a través del wifi, como por ejemplo WiFi Tracking Figura 4.
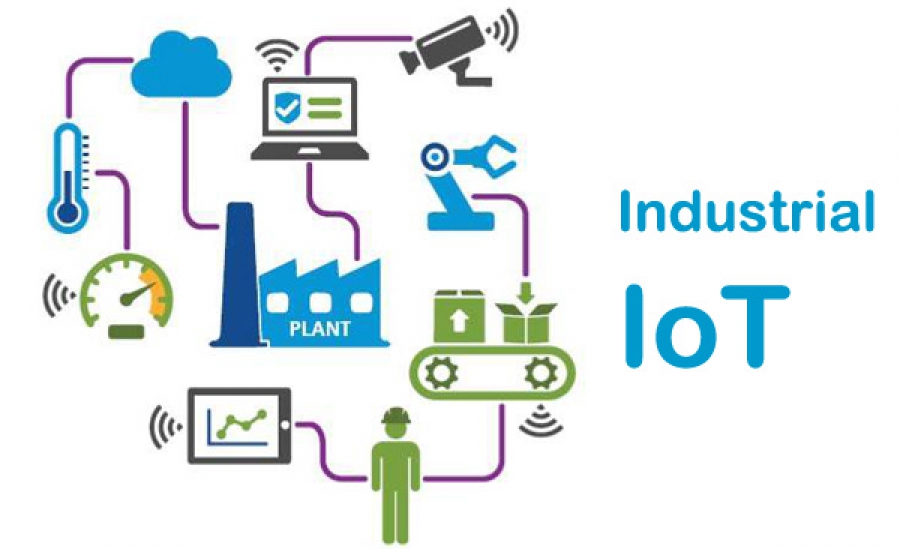
A su vez, existe un derivado de las iot que se dedican especialmente al sector industrial, denominadas como IIoT consiste en maquinaria conectada a Internet y en avanzadas plataformas de análisis que procesan los datos que se producen. Los dispositivos IIoT van desde diminutos sensores ambientales hasta complejos robots industriales. Si bien la palabra «industrial» puede referirse a almacenes, astilleros y fábricas, las tecnologías IIoT son muy prometedoras para una amplia gama de sectores industriales, como la agricultura, la sanidad, los servicios financieros, el comercio minorista y la publicidad . Pero se diferencia principalmente con las Iot convencionales en que, a pesar de ser una subcategoría del Internet de las cosas, que también incluye aplicaciones orientadas al consumidor, como dispositivos portátiles, tecnología doméstica inteligente y automóviles sin conductor. La característica distintiva de ambos conceptos es la infraestructura, las máquinas y los dispositivos integrados en sensores que transmiten datos a través de Internet y se gestionan mediante software.
Figura 5.
El incremento de dispositivos para proporcionar una mayor inteligencia a los procesos industriales y el uso de técnicas específicas para el tratamiento de datos han supuesto una serie de ventajas con respecto a la industria más tradicional. Algunas de esas ventajas se comentan a continuación:
– Mejorar la eficiencia energética y mantenimiento predictivo y preventivo de las máquinas, donde podremos obtener, de forma más rápida, datos de los sensores y otros dispositivos IIoT para realizar un seguimiento de su funcionamiento de forma constante y, de esta manera, poder prevenirnos ante un posible fallo. – Mejorar la conectividad respecto a las redes de comunicaciones, esenciales entre el dispositivo y el sistema IIoT dentro del cual opera. En este punto podemos encontrar varias partes: Utilizar una segmentación apropiada para el uso de IIoT, como se indica en las buenas prácticas. La seguridad de la red mediante un buen modelo es esencial. El Modelo de Purdue para la jerarquía de control es un modelo bien reconocido en el entorno industrial, ya que segmenta dispositivos y equipos de una manera jerárquica. – Comunicaciones en tiempo real, lo que implica una necesidad de tener una conectividad continua, además de poder almacenar los datos obtenidos para volver a revisarlos, si fuese necesario. Iniciación de las comunicaciones de manera segura para que no haya ninguna posible intrusión por parte de un tercero. – Seguridad de enlaces: se centra en el nivel de seguridad y confianza que implica el establecimiento y el funcionamiento de la conectividad. – Uso de la nube para almacenar datos y facilidad de acceso mediante otros dispositivos para acceder a ellos.
Cómo ya hemos mencionado anteriormente, las conexiones que permiten el corrector funcionamiento de las Iot, son las redes, las mas llamativa son el conjunto formado por las LPWAN, denominado de esta manera debido a (Low Power Wide Area Network), son redes de amplia y baja potencia, son un protocolo de transporte inalámbrico de datos que hoy en día se entiende como uno de los protocolos básicos para la implementación de IoT. Las redes LPWAN trabajan en una banda ISM libres sin necesidad de licencia, siempre y cuando se respeten las restricciones en los niveles de potencia transmitidas. Representa un espectro que se reserva al uso no comercial asociado con la industria, la ciencia y los servicios sanitarios Dentro de estas existen numerosos tipos:
Figura 6.
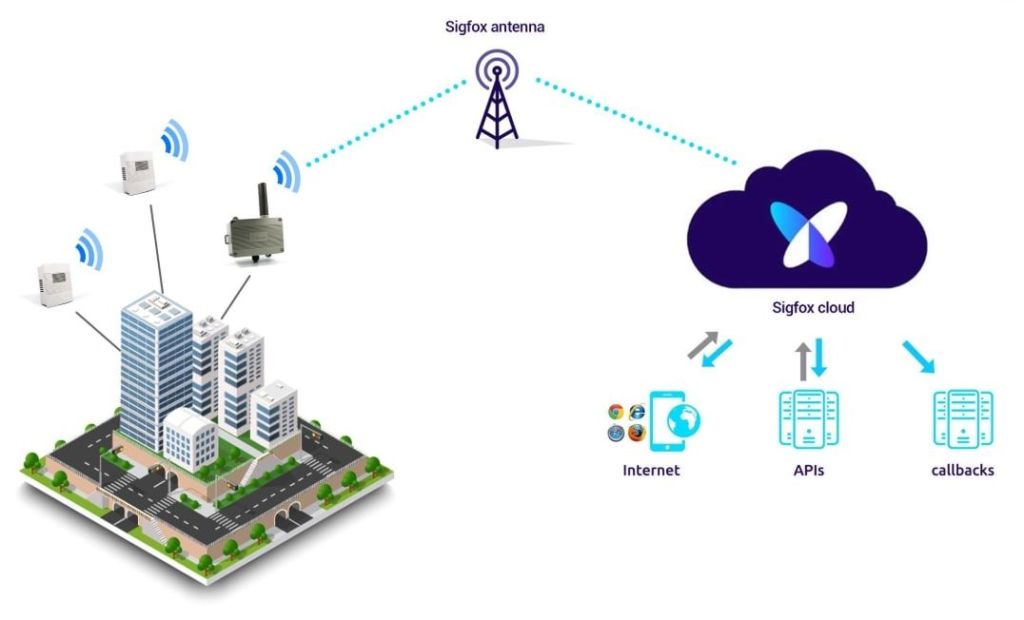
Sigfox: Creada por una empresa francesa, que están diseñadas para conectarse a dispositivos de baja energía. Estas redes utilizan la banda ISM ultra-estrecha para la que no es necesaria licencia por debajo de 1 GHz . Para poder emplear este tipo de red, la empresa afirma que los clientes necesitan cumplir los siguientes requisitos : Un módulo que se entienda con la propia red ; Una suscripción válida y encontrarse en un área de cobertura. Cada nodo de la red, puede cubrir un área de cobertura bastante grande. Además, permite que empresas que necesiten mejorar la cobertura en su área pueden instalar un equipo repetidor.
Funcionamiento de una red Sigfox. Figura 7.
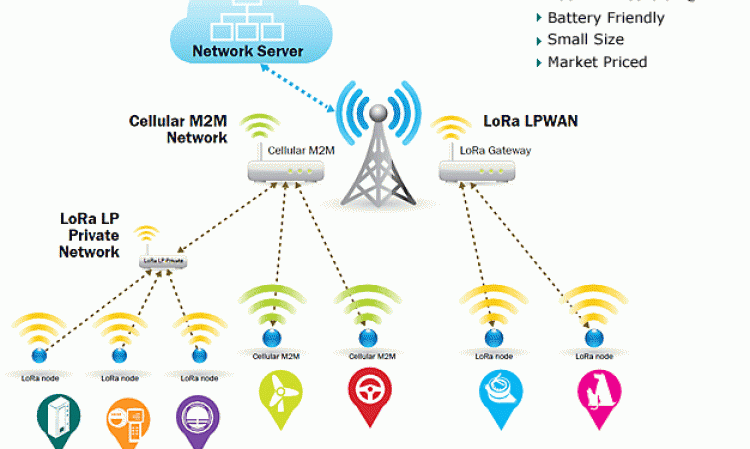
LoRaWAN : Proviene de LoRa es una tecnología inalámbrica (al igual que WiFi, SigFox o Zigbee) que emplea un tipo de modulación en radiofrecuencia patentado por Semtech, una importante empresa fabricante de chips de radio. La tecnología de modulación se denomina Chirp Spread Spectrum (o CSS) y se ha empleado en comunicaciones militares y espaciales desde hace décadas. LoRaWAN es un protocolo de red que usa la tecnología LoRa, para redes de baja potencia y área amplia, LPWAN (Low Power Wide Area Network) empleado para comunicar y administrar dispositivos LoRa. El protocolo se compone de gateways o nodos, los gateways (antenas): son los encargados de recibir y enviar información a los nodos, y los nodos (dispositivos): son los dispositivos finales que envían y reciben información hacia el gateway. Su infraestructura es de código abierto, que a diferencia de Sigfox, permite a otras compañías crear sus propias redes IoT basadas en sus especificaciones tecnológicas. Su tecnología está basada en permitir que una estación base o central, sirva para cubrir muchos kilómetros. Rango que depende del medio en el que se encuentre. Es una red bidireccional. Las velocidades de datos oscilan entre 0,3 y 50 kilobits por segundo. A su vez, existe un variante de esta red, denominada LoRaWAN (Long Rage), caracterizada por su poco consumo, puesto que solo se activan periódicamente, lo que permite que la batería perdure a lo largo del tiempo ; Su alcance es tal , que puede llegar hasta puntos que tienen dificultades, como los sótanos etc.
Funcionamiento de una red LoRaWAN. Figura 8.
¿Porqué debemos utilizar las IOT?
A pesar de su mala reputación, por ser empleadas para el estudio y espionaje de las personas, estas tienen numerosos beneficios, que nos hace plantearnos su uso, en concreto, las que salen mas beneficiadas de su uso son las empresas : Mejoran la eficiencia, puesto que por medio de las Iot pueden controlar el seguimiento de producción de sus productos. «Los sensores de IoT ya son comunes en la industria manufacturera, pero su potencial aplicación no se limita a este ámbito. Pueden usarse para monitorizar procesos que tienen lugar en multitud de espacios, como puede ser una oficina convencional. Los dispositivos de seguimiento se pueden conectar a dispositivos portátiles para mejorar la distribución o reducir las pérdidas y los termostatos controlados por aplicación» ( Scott Arpajian , Los beneficios reales del IoT para empresas y clientes, El País Economía, 23 de Enero 2019).
A través del IoT las empresas, consiguen realizar un control en tiempo real de todos los activos. De esta manera, se localizará al momento cualquier incidencia que interfiera en el rendimiento de recursos y equipos.
Uno de los beneficios más importantes del IoT para las empresas es la oportunidad de aprovechar al máximo un mercado que está en constante cambio. Con la incorporación de nuevas, modernas, y ágiles metodologías , la adaptabilidad de las empresas será mucho mayor por lo que estas variaciones le supondrán un beneficio mayor.
Los dispositivos IoT pueden ayudar a las compañías a evaluar con precisión la demanda que tiene un cierto producto. Del mismo modo, se reducen las tareas repetitivas, por lo que los empleados pueden dedicar su tiempo a desempeñar funciones más productivas, lo que le supone a la empresa una mejora del rendimiento del personal.
En la industria el uso de estas también conlleva numerosos beneficios como : el abaratamiento de costes, la implementación del IoT, permite el ahorro de costes gracias a la automatización de las cadenas de producción; El uso proactivo de los datos, conectando las máquinas a Internet, las organizaciones pueden controlar grandes volúmenes de datos. Eso les permite pronosticar fallos y reducir costes de mantenimiento, mejorar la eficiencia y la disponibilidad. A medida que las capacidades de los dispositivos conectados a Internet avancen, se volverán más útiles al combinar los datos con la información; Optimización de procesos, gracias al IoT, personas y datos se integran entre sí para ofrecer un valor. Las conexiones aportan un valor, puesto que cada información llega a la persona adecuada en el mejor momento y de la mejor manera posible.
¿Cuál es la relación entre Iot y BigData?
Una de las consecuencias de que el Internet of Things exista es la enorme cantidad de datos que se producen, que son analizados, a través de la tecnología de BigData, con el fin de ofrecer mejores servicios al usuario. Entre las nuevas disciplinas que encontramos actualmente, el Big Data, que se puede definir como las gestión de una variedad, volumen y velocidad de datos transferidos, que permite conocer más a fondo a cada uno de los clientes actuales o potenciales de una empresa. El Big Data actúa de manera paralela al Internet de las Cosas, IoT, que no es otra cosa que la interconexión entre dispositivos digitales, máquinas, objetos, animales y personas que se comunican entre sí a través de una red, como ya habíamos mencionado con anterioridad.
Con el IoT avanzamos hacia un futuro en el que los sensores inteligentes pueden detectar el entorno en el que se encuentran e interactuar con sus propietarios y entre ellos. Ese flujo de datos entre dispositivos y personas es lo que alimenta los sistemas de Big Data.
Por ello, las empresas deben marcarse como prioridad el rendimiento máximo del uso de sus equipos, de forma óptima y eficiente para ganar en rentabilidad y conseguir una mejor imagen frente a sus clientes. Para ello es fundamental contar en sus equipos con expertos en disciplinas como el IoT y el Big Data.
En primer lugar cuando se crea un blog, se debe tener en cuenta con que intención queremos hacerlo. Teniendo en mente una ligera idea del tema a tratar, debemos elegir el tipo de blog, en función de a que público queremos dirigirlo, bien sea un ambiente mas profesional, o simplemente uno informal. En el caso de nuestro blog lo dirigimos a un público menos profesional.
Fuente propia.
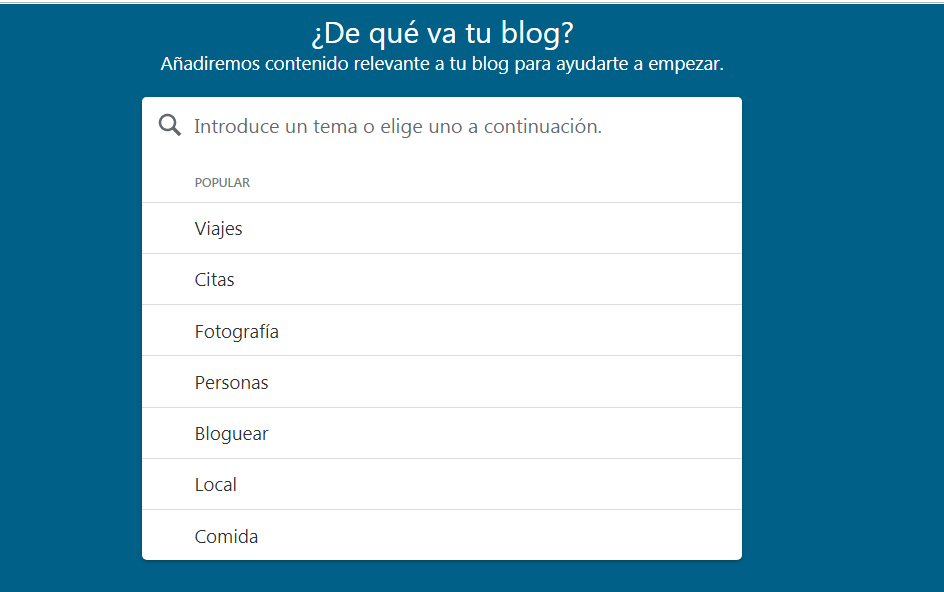
Una vez elegido esto, debemos tener claro la idea a tratar en nuestra página, es decir, de que queremos compartir, cuya finalidad sea didáctica, porque como dijo el filósofo inglés Thomas Huxley «Intenta aprender algo sobre todo y todo sobre algo». Para nuestra página web en cuestión seleccionaremos el ámbito de bloguear puesto que trataremos distintas cuestiones en este blog.
Fuente propia.
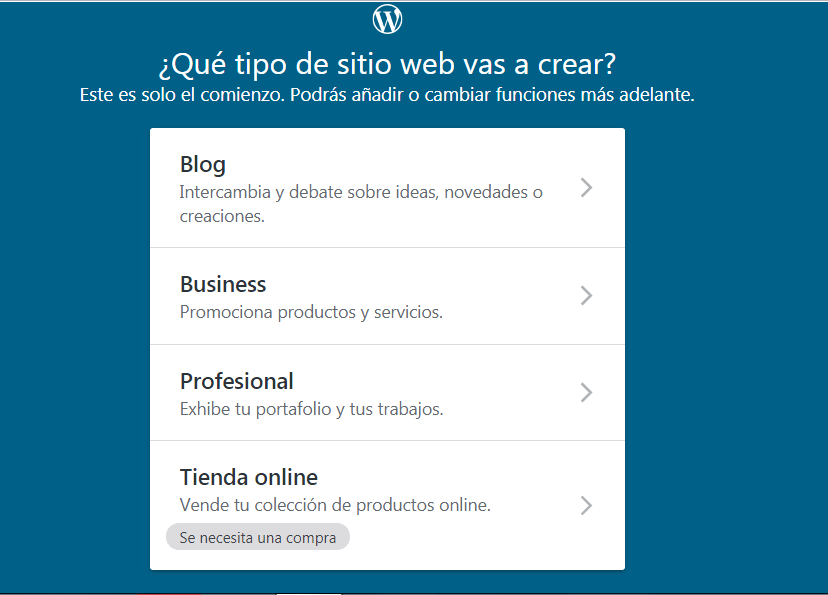
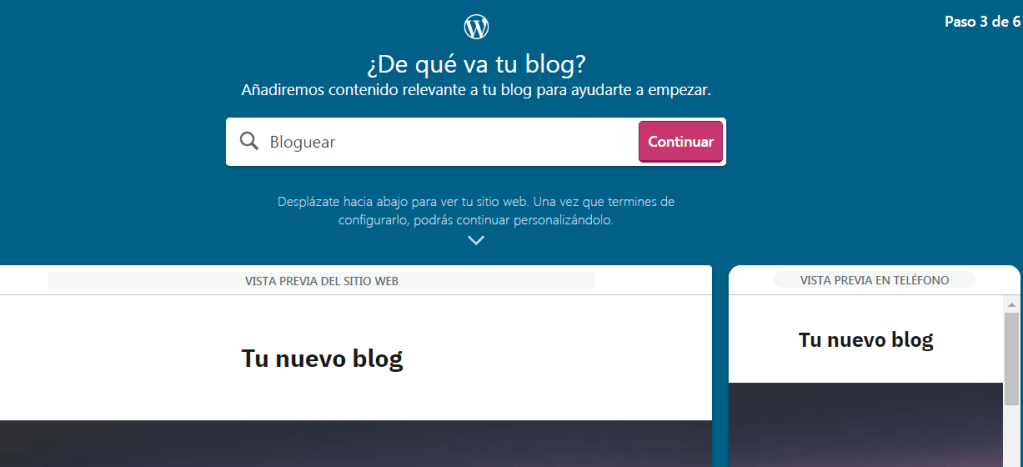
A continuación se mostrará, la primera vista previa de nuestro nuevo blog, para hacernos a la idea del resultado final, una vez seleccionada la categoría en el paso anterior, se mostrará esta misma en la barra del buscador de la web y debemos darle a continuar, puesto que ya lo hemos elegido anteriormente.
Fuente propia.
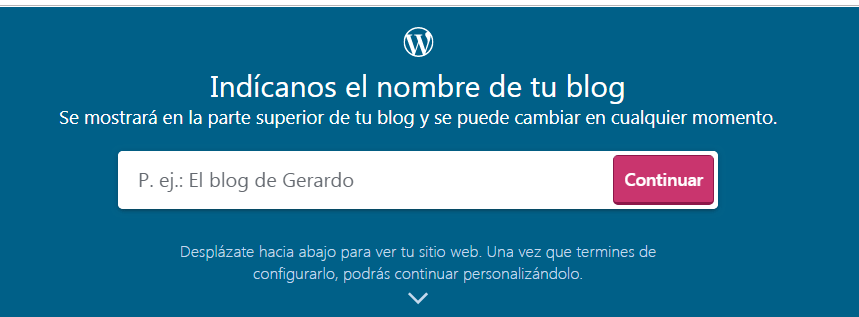
Una vez meditados todos los pasos anteriores, debemos nombrar nuestra web, si queremos ser originales, le pondremos un nombre en concordancia con nuestro tema a tratar, lo que a su vez resultará mas fácil para aquellas personas que busquen información o soluciones sobre el tema. Pero a su vez se le puede dar un toque mas personal añadiendo el nombre del autor en cuestión. Nosotros le denominaremos como TechTIC, puesto que nuestro blog trata principalmente de tecnología que a su vez son las TIC.
Fuente propia.
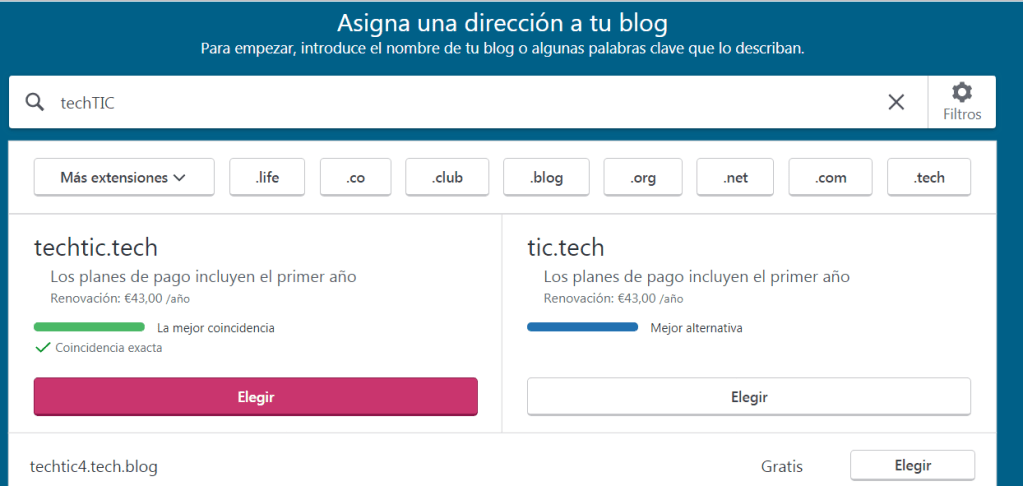
Una vez elegido el nombre con el que se dará a conocer la página, le designaremos una o dirección web propia, en mi caso, he decidido atribuirle una URL que guarde relación con el nombre de mi página web. Para ello simplemente he puesto el nombre de la futura web en el buscador y le he atribuido la web que mejor me convenía, al no tener ningún presupuesto detrás, he optado por la sugerencia gratuita.
Por último y al dejar claro que no hay ninguna intención empresarial ni nada por el estilo, simplemente con la intención de aprender a crear una página web propia, he optado por elegir «Empieza por un sitio web gratuito.» y con esto el programa comenzará a crearnos la página, que estará a nuestra disposición en breves instantes.






























{kind=link}
{kind=link}